Building a reliable events system
Building reliable events systems
As you start to think about whether you need an event or real-time streaming platform, everyone starts in a similar place:
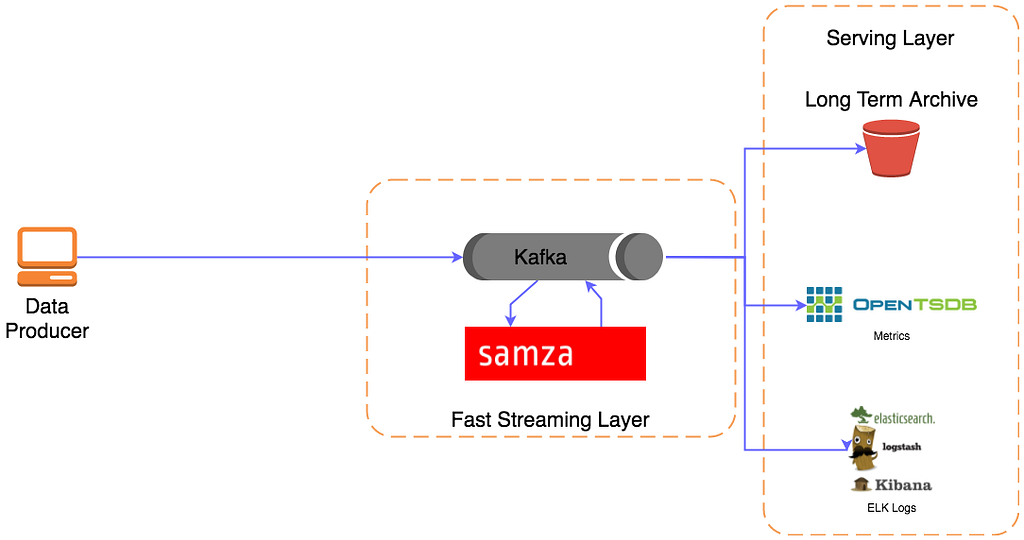
Kafka, Samza, OpenTSDB, ELK just for illustration here — a common example but have many alternative and comparable options.
This is both a great and the most natural place to start so you’ve not gone wrong yet, but you will quickly discover that this isn’t necessarily the perfect solution. As you start sending some real data in you’ll discover that sometimes messages get lost, or perhaps as you integrate it into hundreds of different microservices you realize that it’s a lot of effort adding a publishing client to all of them individually so you can offload events.
99% uptime and reliability achieved here, but let’s see how we can improve it.
These problems are initially easy to improve, you can start by building a wrapper around your producing client. This can pin the version of the library that you’re using, it can inject default config and retry policies to help ensure that messages get sent reliably, and hopefully, make it a bit quicker and easier to drop into your new applications. A key new issue that this introduces though is support for multiple languages. Not only do you need the producing library available in multiple languages, but you must have built your wrapper (and keep it updated), for all the languages you wish to make easy. Without getting into specifics about microservices being language agnostic or locked, this is naturally going to be more effort to maintain.

Now that you’ve got a good flow of events running through your platform, you have to start thinking about maintaining and scaling it — this seems like a good point to improve that initial streaming system you just threw up, improve some config, and make sure it’s ready to support all this data. You get ready to upgrade Kafka, improving the configuration, supporting the latest compression and speeding up the message offload from the clients, when you realize that now all your clients need to update too. The past month has been spent just getting teams to adopt the library so far, get it implemented and sending messages, and now they’re all going to have to upgrade, when you’ve released updates for all your supported client libraries that is. In the worst-case, perhaps this upgrade is a breaking change and you now have the hurdle that you can’t upgrade your platform until you’ve tracked down every last producer else they’ll suddenly stop working.
What you have achieved at this point, will be moving towards 99.9% uptime and reliability — the more consistent sending practices, consistent retries and message building that you’ve now deployed to your clients have provided a great improvement.
Given you’re going to have to coerce everyone to upgrade next, you try to think about how you can better isolate your users from the core technology that you’re using, perhaps you want to swap it out in future or change some architecture without having to force everyone else to upgrade first. You start to consider how making HTTP web requests could give you a much more stable and consistent interface into your platform; that way any tech choices can be contained and isolated within your platform’s boundaries. This much more embraces having an API as your public interface, allowing you to keep the internals within your complete control.
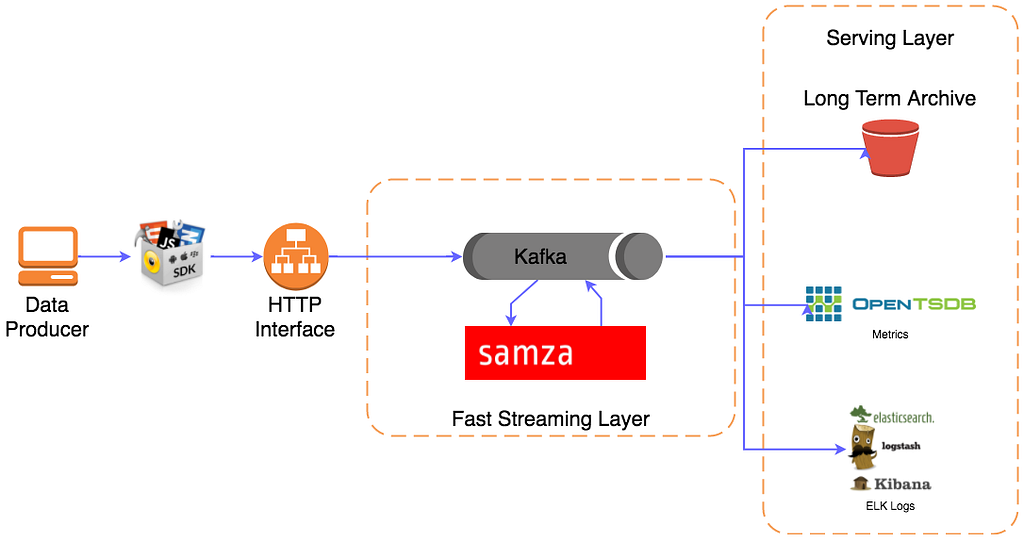
Pushing forwards you quickly get a web service that will receive requests, repackage them into the format for your streaming system, and offload them, ensuring that it only sends a successful response once the platform has confirmed that the message is successfully received and persisted.
We’re now pushing towards 99.99% uptime and reliability, the API layer gives us a buffer and consistent handoff into our streaming layer; we can also have further retry logic to aid with consistent handoff, and by applying backpressure we can start to provide consistency guarantees via responses from the API.
The platform is now running nice and stable, you’re getting comfortable making config changes in your streaming system, and lots of teams have embraced using the system. Eventually, one of these config changes doesn’t quite work correctly and your events system goes down. Your API starts to reject messages, everything sent to the system is being dropped, your producing applications are starting to go offline from memory exhaustion due to their retry policies, and you now have a complete site outage. What happened?
Your initial config for reliability has worked great up until now, but when you set your library to have 1,000 retries, it’s now having to store lots of messages in memory that just can’t be offloaded anymore. Also, due to the backlog, your platform is trying to stabilize but every time it gets stable and the API starts to come back online it’s hit with hundreds of thousands of queued requests from all your services, it’s instantly swamped and falls over again.
As we attempt to approach 99.999% of uptime, which gives us roughly 4minutes a month to work with, this doesn’t allow for a service outage that relies on any kind of remediation action. This leads us to think about having redundant systems. There are lots of ways to do this, all with various complications, and the values vary depending on the scenarios that you’re trying to protect against. Going geographically diverse is a common thought train here, but only strictly necessary if you’re looking at protecting against a whole region outage. If the focus is more about protecting against system downtime, it’s quite possible to just have a diverse path running in parallel to the same system. You do need to carefully consider any shared components, but there are plenty of potential options to avoid having to geographically distribute — and then recombine — your data.
Following that train of thought, let’s look at an option:
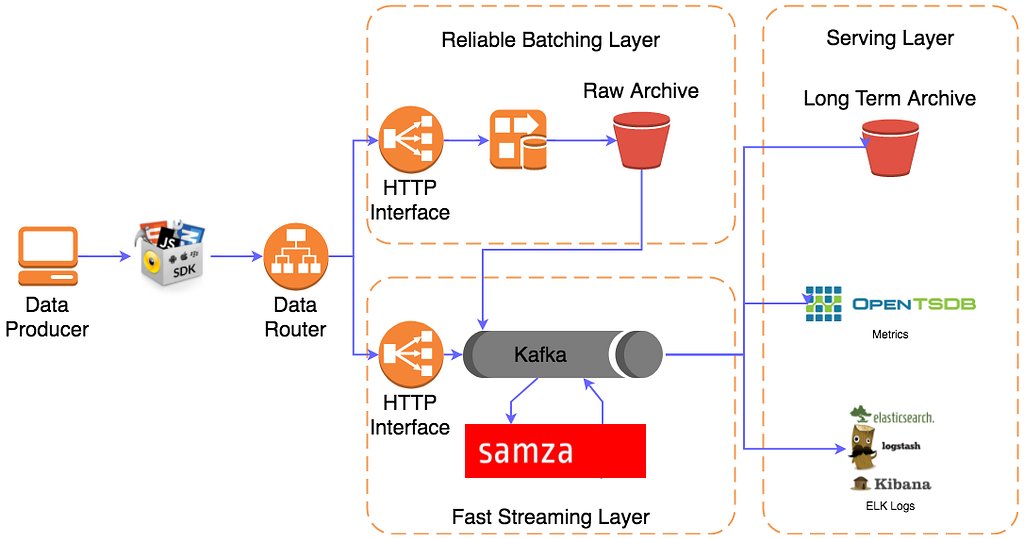
Here we’ve added not only a second path of data capture, but we’ve also introduced a Data Router in front of our HTTP Interface, this gives us the option to do smart routing of data based on its need, health checking of the downstream systems, and dynamic switching of where it’s data is being sent.
To look at the new data capture layer that we’ve added, the key characteristic that we see is simplicity, the primary goal is solely data capture, no potential for stream processing, no extra consumers reading from it, the only focus is data capture and then ensuring it’s persisted. After this, we can now replay data out of that archive and through the streaming side of the system, in case of any instability downstream it’s now possible to simply replay that data into the system. This extra layer having fewer moving parts, and a sole focus on persistence means it’s a great path to send our most important data, which is what we then look to configure in the router.
The router can be set up to send a subset of your events, the most important datasets, through the extra persistence layer; by limiting this down to just the most important data, you also cushion yourself from many scaling concerns — while you can still apply any learnings from your streaming layer into the persistence layer, it will hopefully have to deal with many fewer messages which once again helps to keep it simpler and more reliable. In case of a failure of this persistence layer, perhaps a configuration error when updating that route, it can still hand messages off directly into the streaming side to again minimize the chance of any data loss.
With this, you can now more easilly aim for 99.999% uptime and reliability given the assurances you have of data capture. In failure scenarios, you may encounter slightly longer delays on data arrival, but that’s a tradeoff you can now choose to make verses data loss.
This is a super high-level view of one particular way to build a reliable data ingestion system, but some things to think about when you’re getting started that it’s not always as simple as just plugging your services directly into the stream!

Michael Pollett
Bio LinkedIn DNS CAA Tester Domain Registry