Stop Building Your Platform Around Kafka
Before you get the wrong idea, I’m a big fan of Kafka. It does a great job but all too often it’s setting your architecture up for failure.
So, what is Kafka good at?
High performance and throughput — Kafka is great at handling large volumes of messages concurrently and dealing with disparate consumers sending and receiving from it
Data persistence — replication and automatic failover of partitions is ideal for ensuring your data is safe and can provide accurate feedback on whether messages are persisted
Asynchronous messaging — the ability for one service to fire and forget a message, and another to pick it up when it’s ready is well catered for, this isn’t specific to Kafka, but in its comfort zone
(and more)
This sets Kafka up to be at the core of your system, your services can plug into it, they can offload messages, and then they’re stored and readable as needed.
But what have you ultimately done? You’ve turned Kafka into an Enterprise Service Bus.

Don’t use Kafka as an Enterprise Service Bus
An Enterprise Service Bus is an older term now, Wikipedia will tell you it’s from around the turn of the century. The relevance is that it’s exactly this model of building your services around a central service, lots of input and output from that one service, and using it as a routing and processing engine. The key issue here is that whilst Kafka is a redundant, reliable system, you are still building it into the all-seeing, all-knowing centralized service that everything hangs off.
As with all services, failure is inevitable, things can be well built, hugely scalable, nicely distributed, but eventually, be it by strange accident or human failure, something will go wrong. This is the point that your microservice architecture will be there to save you.
Microservices will save you because they’re built around point to point communications, they use distributed architecture to remove central points of failure. Still working on the premise that failure is inevitable, you should be looking at your services thinking if a particular service fails, it will affect this defined segment of functionality, but all the other services that don’t require it will continue to work as normal.
If all your services depend on a central Kafka, Kafka failure could cause you a complete systems failure, so from a reliability point of view, you’ve built your typical distributed monolith. A complete failure isn’t necessarily the only outcome here, but if all your systems rely on a single component, then you have a large and central dependency that could be detrimental to your whole platform.
Understanding your data patterns
Central failure isn’t your only concern, Kafka itself has plenty of tuning and customization that you can do, generally either choosing to set your cluster up to optimize for reliable offload and high throughput or opting for reliable storage and delivery. In its simplest form, this comes back to your settings around in-sync replicas, and unclean elections. The important thing here is that a single Kafka setup isn’t going to solve every use case.
A brief look at CAP theorem tells us that we can only aim for two of Consistency, Availability, and Partition tolerance, if we need a system that guarantees high throughput and always being ready to take messages, we would look to sacrifice consistency, if we’re after a system that guarantees consistent delivery, we should sacrifice on availability and apply backpressure principles to tell the producer that we’ve not saved their messages.
Isolated use cases
Starting to look at systems that can implement this model, let’s first plan out a logging system.
- We must receive logs from various system
- It should deal with a high message rate
- Speed of delivery is important as we want to see our logs soon after they were triggered
- A missing log could be annoying but given logs are for human analysis and often generated multiple times this won’t be a critical system issue
Our Kafka setup here might look like:
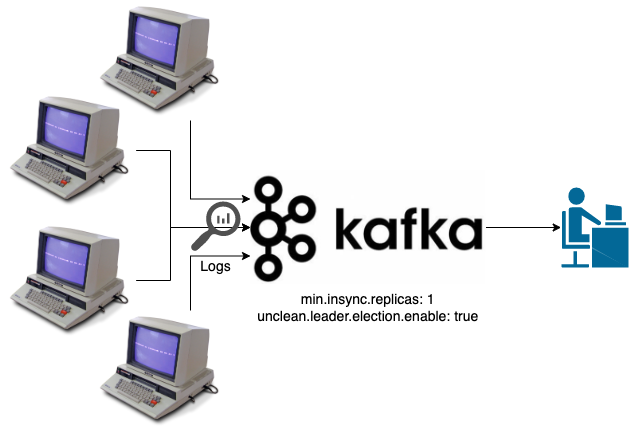
We’re opting for a low acknowledgment here, if your data is truly throw-away you could even disable the need for acknowledgments. Also allowing unclean election optimizes for the latest data to arrive if there’s an issue we don’t mind losing some previous data to get back to real-time.
Our alternate use case might be for a cluster of services that want to rely on event sourcing to share their data.
- We need high consistency and reliable message storage
- Data producers can buffer messages until they’re acknowledged
- Order of the messages could be important
Our setup here might look like:
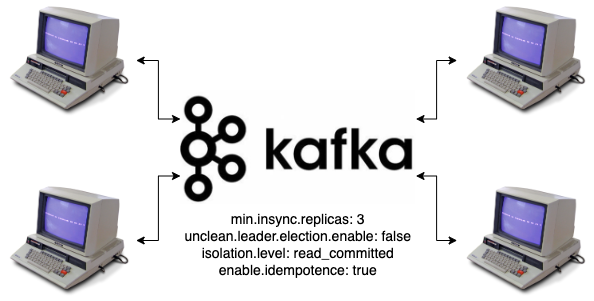
In this setup, we want to ensure that data exists on multiple nodes, and we want to ensure that we keep a correct history, again pushing back on the producers if the cluster can’t reliably store that data at the moment. We’re also adding in config for exactly-once write semantics, and ordering guarantees. This is an added bonus but could be useful depending on the use case.
Full ideal system
Our previous diagrams have fallen into the usual misdirection of showing single parts of a system, this is how you often see diagrams of Kafka, showing specific data flows or a segment of the system, what this diagram might actually look like if these were part of a wider system, might be:
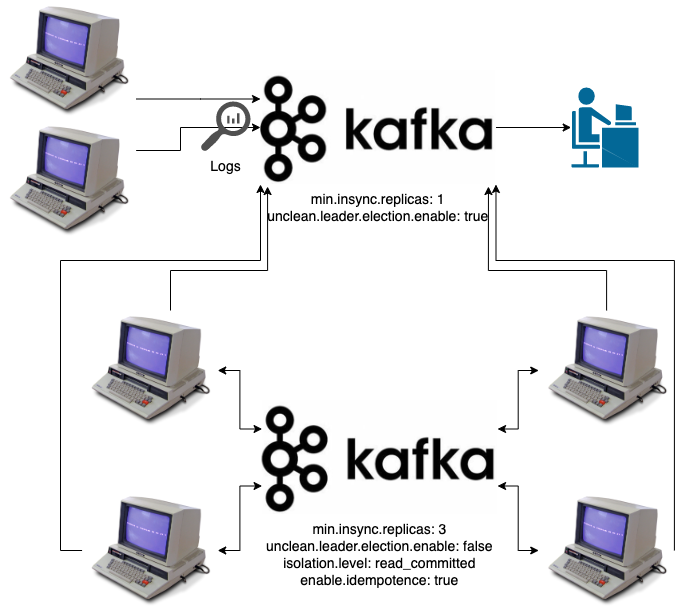
This is still a simplified diagram, but notably depicts that we can share Kafka use across multiple systems, the key point is that each Kafka cluster has a specific purpose; one that they all feed into is our system for log processing, the latter one attached to only the systems that are part of that event sourcing setup. Each cluster is configured and exists for its own specific purpose.
This will naturally become much wider and more complex as other use cases and independent systems are added.
But we’re a startup/PoC/limited time/just testing
As with all compromises, this one exists too and is down to you to decide, but at least knowing the risks will help you make the tradeoffs.
Can you ignore everything I’ve said and throw all your data at one cluster?
Yes!
Will this continue to work for some significant amount of time as you build and strap more and more services around it?
Most likely.
Will it be cheaper/easier to setup/easier to maintain one cluster?
Probably/likely/maybe.
But… the key thing you should be thinking when you make this decision is that it’s a tradeoff. You are building tech debt, it’s likely fundamental tech debt at the core of your system that will influence the design of your other services, and one day in a failure scenario, it will have a clear cost.
Conclusion
We’re now about done with the important info, but here’s a bonus extra example of having made this m̶i̶s̶t̶a̶k̶e design decision…
The remit when starting that project, was to build a system to improve Skyscanner’s ability to make data-driven decisions. Naturally, this meant metrics would be a very key part of the system, we embraced system logs to go with that for some low level derived metrics, then while building out the system it quickly evolved to include custom event messages from other systems in the platform. This was added while initially struggling to get traction of users on the platform and was an extra use case that helped us to get teams on board.
We built the platform to cater for all those cases, but as you consider our previous considerations around data patterns, these are different cases. We’ve already touched on logs as opting for speed over completeness, metrics can fall into the same category given they’re sent regularly and gaps can be extrapolated, but as soon as we look at those custom metrics they need different semantics. An example being the same platform used for financial tracking and reporting, losing messages isn’t good for this case!
A quick look down the bottom of my post on reliable events systems gives an idea of our final architecture, but the key thing you see is that it’s effectively 2 systems to deal with the 2 use cases, strapped together in the guise of one system. It took us some time to get there, but if we’d been able to call out earlier the different data requirements then perhaps the outcome would have been different.
Go take a read if you’re keen to see how that evolved:
Building Reliable Events Sytems
While the above diagrams are valid configuration items, they’re not exhaustive and are a mix of cluster, producer and consumer config, so do your own research!
Similar reading:
- Apache Kafka vs. Enterprise Service Bus (ESB) | Confluent
- Recreating ESB antipatterns with Kafka | Technology Radar | ThoughtWorks
Stop Building Your Platform Around Kafka was originally published in codeburst on Medium, where people are continuing the conversation by highlighting and responding to this story.

Michael Pollett
Bio LinkedIn DNS CAA Tester Domain Registry